ソート済の整数列に対してlower_bound(x)メソッドを使うと、目的の整数xを探し出せることは誰でも知っています。
そこで使われているアルゴリズムが二分探索と呼ばれて、その計算量がO(log N)であることも誰でも知っています。
標準ライブラリを使ってポポポポーンです。
しかし、競技プログラミングに入門するとまずぶち当たるのが 「条件に対して二分探索を行う」という考え方です。 上で挙げた「整数xを探す」と本質的には同じことなのですが、整数という具体的なものではなく 条件に置き換わってしまっているため、一段飛躍があります。 逆にいうと、この飛躍をなくせば、有利になります。
これは度々出題される上、応用範囲も広いため、完全に理解するとよいです。 そこでこの記事では、二分探索をフレームワークとして抽象化することを通じて、 二分探索を完全に理解します。
二分探索とはFalseとTrueの境界を探すことである
二分探索というのは、ソートされたbool列の中から、FalseとTrueの境界を探す行為に他なりません。
このようなbool列を出力する関数をf(int) -> boolと置くことにしましょう。
ソートされているということはどういうことかというと、f(3)=False,f(5)=True,f(6)=Falseのように
一旦TrueになったあとにFalseになることがないということです。
これを、「(広義)単調性」といいます。
二分探索を疑う問題文の形として「条件を満たす最小のxを求めよ」というのがありますが、これはその問題が
f(x<minx)=False, f(x>=minx)=Trueであるようなminxを探すことに帰着出来ることを意味しています。
言い換えると、「xが大きければ単調に有利になる」という性質があるということです。
従って、このような性質があるかどうか考察するところが第一歩となります。
この関数f(x)を以下のようにFとTの列で表すことにします。 目的は、FとTの境界を探すことです。
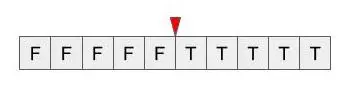
初期の探索範囲と解
探索するには、「初期の探索範囲」を与えて、その範囲を徐々に狭めていって 目的の境界に近づいていきます。
この初期の探索範囲の与え方は、以下の3通りA-Cがあります。
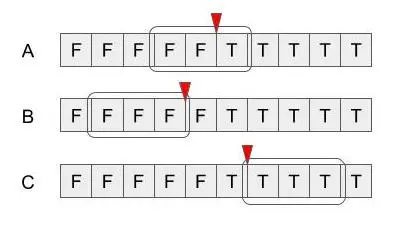
Aは探索範囲に目的の境界が含まれている場合で、B,Cは含まれていない場合です。 Bは探索範囲がすべてFalseの場合で、この場合は、右端を境界とするのがよいといえます。 (それより右にTrueが並んでるとみなして考えます) 逆にCは探索範囲がすべてTrueの場合で、この場合は左端を境界とするとよいです。
探索範囲の狭め方
探索では、左端と右端の中心midをとって、
その地点の計算f(mid)の結果を利用して探索範囲を狭めていくのですが、
計算の結果によって狭め方が変わります。
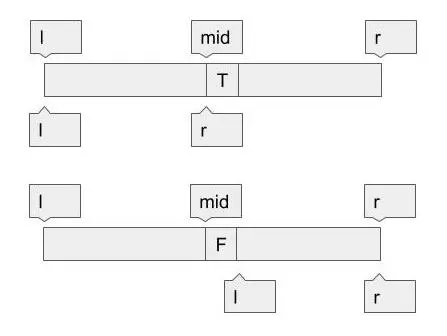
まず、計算結果がTrueの場合、境界はそこより左側にあることになりますから、r=midとします。
逆にもし計算結果がFalseの場合、境界はそこより右側にあることになりますから、l=mid+1とします。
こうしていくと、最終的に左端と右端が一致し、そこが求める境界となります。
実装
| |
整数の個数を探す
冒頭に紹介した整数を探すlower_bound(x)というのは、
このフレームワークでいうとどういう場合に相当するかというと、
f(i) := a[i]>=xという関数の場合だといえます。
さらに、upper_bound(x) - lower_bound(x)を計算すると
数列中のxの個数が計算出来るというのはどういうことか考えます。
upper_bound(x)というのは、
フレームワークでいうと、
f(i) := a[i]>xの場合(等号はなし)といえるのです。
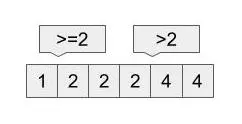
こう考えると、xの個数が計算出来ることがわかります。
半開区間に馴染みのない人はこちらも読んでください。 配列の範囲の表現方法「半開区間」を解説