この前、 最近仕事がピリっとしないため、 分散ストレージの中でデータの置き場所を計算するアルゴリズムASURAを実装したことを話した。
データ分散アルゴリズムASURAの実装その後も、引き続きピリっとしないため、 このままでは死んでしまうと思い、 生きるために分散ストレージを開発した。 まだWIPレベルだが、基本的な方針は固まったため、 簡単なドキュメントとともに初版を公開した。 とにかく2週間くらいで一気にやったので、あまり眠れず、死ぬかと思った。
名前
まず名前についてだが、さんざん悩んで紆余曲折があったのち、Sorockに決定した。
Sorockというのは、
- So rocking: イカしてる
- Soroku Ebara
をかけている。 このうち後者は、おれの出身校である麻布学園の創始者の名前である。
いつか、自分のストレージソフトウェアを作るとしたら、 愛する麻布学園にちなんだ名前をつけようとは思っていたのだが、 まさか創始者の名前が天から降りてくるとは思っていなかった。 しかし、そのままSorokuでは芸がないので、SorokuはSo Rockな人間であったという 謎の解釈により、Sorockと相成った。

実装
Sorockはイレージャコーディングを使ってデータを分割保存する。 このタイプのストレージはCPUがネックになりやすい。
- データの分割、復元計算
- ピースの配置計算
を大量に行うからである。 CPU負荷が高くなるとタイムアウトが発生し、 偽陽性のノード障害などが起こり、運用が困難になる。
また、最大スループットにも影響する。 イレージャコーディングは、ピースを分散配置するため、 データ取得のためのレイテンシ自体は単純なレプリケーションに比べて速く、 仮にその後の復元が猛烈に早いならば、レプリケーションよりスループットが出ることになる。
これらの理由から、CPU負荷が低い実装には価値がある。
イレージャコーディング
イレージャコーディングは、rust-rse/reed-solomon-erasure を使っている。SIMD最適化も提供しており、4GB/s以上の高いスループットを出せることがベンチマークによって示されているらしい。 調査の結果、もっともまともそうなので採用した。
配置計算
ピースの配置計算には、自身が実装したakiradeveloper/ASURA を使っている。このアルゴリズムのよいところは、ノードが増えるほど(例えば100台程度)配置計算のコストが下がっていくことである。 具体的には、1つ計算するあたり疑似乱数生成1回で済むようになる。 以前の記事で紹介したように、ダーツを投げて当たったところを採用するだけなので、 クラスタの大きさNにも影響されない。 例えば、10万台とかそういうスケールになった場合には、 探索コストにlogNが入ってるだけでも相当な負荷上昇になるはずであり、 クラスタの大きさに影響しないことは本物のスケールアウトストレージにとって素晴らしい性質だ。
クラスタ変更時のピース移動処理も、クラスタの大きさには依存せず、定数オーダーであることが数学的に示せる。
クラスタ情報伝播
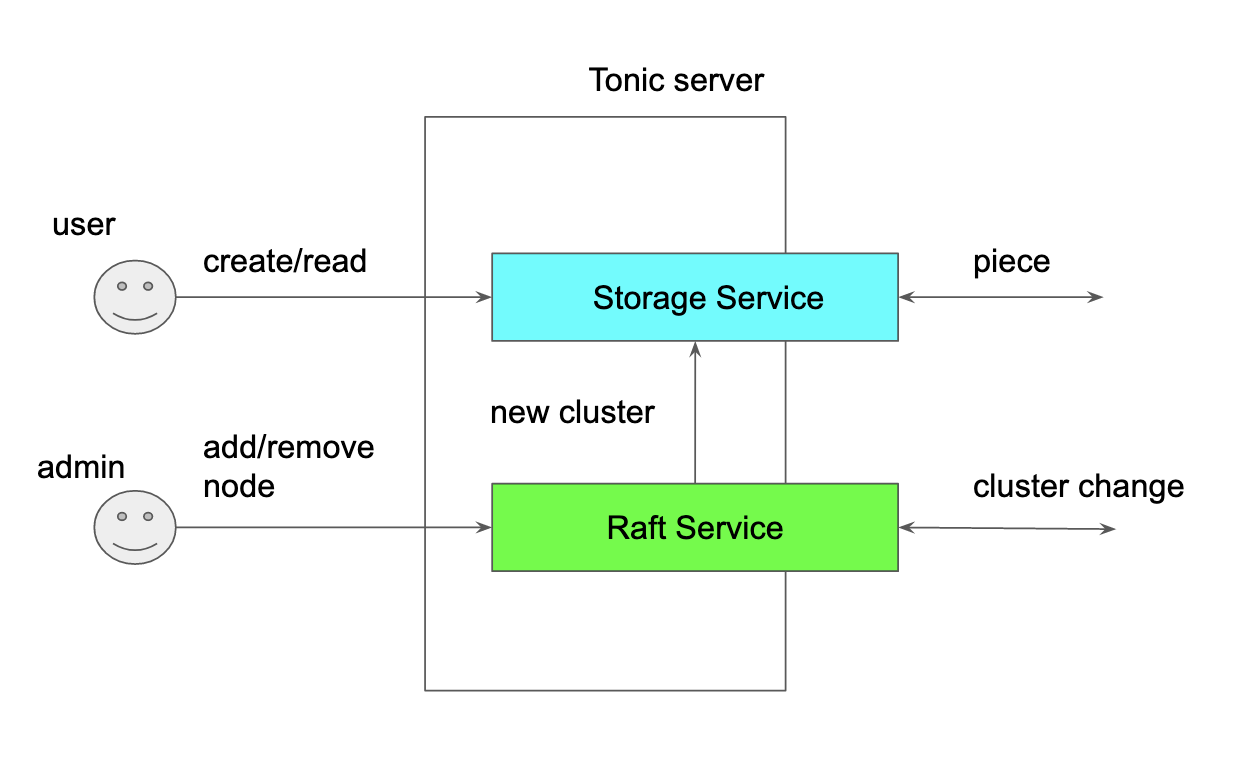
SorockはRustのgRPC実装であるTonicを使っているが。Tonicは複数のサービスをスタックすることが出来る。 Sorockのもっとも低層には、クラスタを形成するためのRaftサービスがある。 これは、自身のライブラリakiradeveloper/lol で実現している。
Raftアプリケーションは、入力されたクラスタ変更メッセージに応じてASURAセグメントテーブルを更新し、 その情報をStorageサービスに渡す。 内部では、akiradeveloper/norpc を使っており、すべてはメッセージングによってやりとりされる。 外ヅラはgRPCだが、中ではnorpcにより非同期サービスが複数動いている。 norpcを使い倒しているのは、Sorockはアーキテクチャの実験でもあるためだ。
Storageサービスは、自身の知るクラスタ情報に応じて、 ユーザからのI/Oを処理したり、ピースの移動・リビルドを行ったりする。
TODO
今後、重要な開発テーマは3つある。
永続化実装とコンテナ化
初版のプログラムは、テストをすべてメモリ上で行っている。 ロジックを確かめる目的であれば、これで十分だからである。
しかし当然、このままでは運用は出来ないため、 ノード内でピースを管理するストレージの永続版を実装する必要がある。 これは基本的には単純なKVSの機能があればよく もっともシンプルな発想としてはファイルシステムを使うというのあるが、 (おそらく性能は出ないだろうが) 他にはRocksDBやsqliteを使うという方法もある。 このようなインターフェイスが実装出来ればよい。
| |
永続化と一緒にやりたいことは、コンテナ化だ。 これは実装があるならあとはやるだけなのでまとめてやりたい。
障害検知
ノードが障害を起こした時は、素早く取り除かれることが望ましい。 なぜならば、障害を起こしたノードへのライトは常に失敗し、常にピースが欠け続けるからである。 これは、データロストの可能性を高めることになる。 ただし、偽陽性(false positive)は出来るだけ避けたい。
このようなアルゴリズムとして一番先に思い浮かぶのはSWIMだ。 SWIMの基本的なアイデアは、pingに応答しなかったノードをいきなりダウン判定するのではなく、 他のノードに別経路でpingしてもらうというものだ。
おれが考えていることは、 基本的に障害検知にはこのアイデアを使う。 独立したクレートとして実装出来るはずである。 プロセスの外とはgRPCで通信しつつ、 中とはメッセージングで通信するようなインターフェイス設計とする。 アプリケーションはアプリケーションの情報を通知するためのSenderを持ち、 ノードダウンを通知されるためのReceiverを持つ。
ライトが完全に成功しなかった場合、 SWIMと同様の理由から、他ノードに対してパトロールリードを要求する。 これは、ライトが成功するかノードがダウン判定を行われるまで再帰的に実行されるため、 ライトデータが消失することはない。
S3やファイルシステムの実装
Sorockは、データのCreateとReadとDeleteしか出来ない、純粋な分散オブジェクトストアである。 これを実運用するためには、S3やファイルシステムなどの側があると良い。 具体的には、これらの側のためのメタデータは他の分散KVSに保存し、データチャンクをSorockに保存するという よくあるアーキテクチャをとる。 既存のOSSと接続するという方法もある。